P(∪i=1∞Ai)=∑i=1∞P(Ai), where Ai are mutually exclusive
What is a Random Variable a map between?X:ω→R
Random Process —> Random Event —> Random Variable —> Probability Distribution
Role of Statistics
When the distribution is known but not the parameter of the distribution statistics helps you figure out the parameter
When does the classical definition of probability fail? When the set of possible outcomes are infinite.
Fischer’s DefinitionEmpirical ProbabilityLong-run relative frequency is considered as definition of probability by RA Fisher
X:No. of goals scored by home teamX∼Poisson(λ);λ:rate parameter;0<λ<∞P(X=k)=x!e−λλx
Here, λ is the parameter of the model, and statistics is interested in finding it out.
The process of searching for the λ is called Estimation
We choose λ values in such a way that P(X=k) from the model will be very close to the empirical probability
Estimation Techniques
Method of Moments (Works on Toy Examples)
Likelihood Method (Powerful)
Bayesian Method (A Method in ML)
Method of Moments
Assume, X=pθ(x), where θ are parameters, and p is either PMF\PDF based on the nature of X, and x1,x2,x3,...,xn are i.i.d samples.
Population Mean: E[X] = ∑x=0∞xpθ(x) = μ1E[X2] = ∑x=0∞x2pθ(x) = μ2
Population Variance: V(X)=E[X−μ]2=E[X2]−E[X]2 = μ2−μ12
The philosophy of method of moments is the sample moments should be close to the moments from the probability distribution pθ(x)
Basically,
μ1(θ)=m1μ2(θ)=m2
and solve for θ
MOM would not work when there are k unknowns but kth moment does not exist
What does it mean for the moment to not exist? When the function inside the summation or integral (in the case of continuous random variables) diverges for a population moment.
Probability Distribution for Continuous Random Variable
Probability Density Functionf(x) is a PDF such that
f(x)≥0
∫Rf(x).dx=1
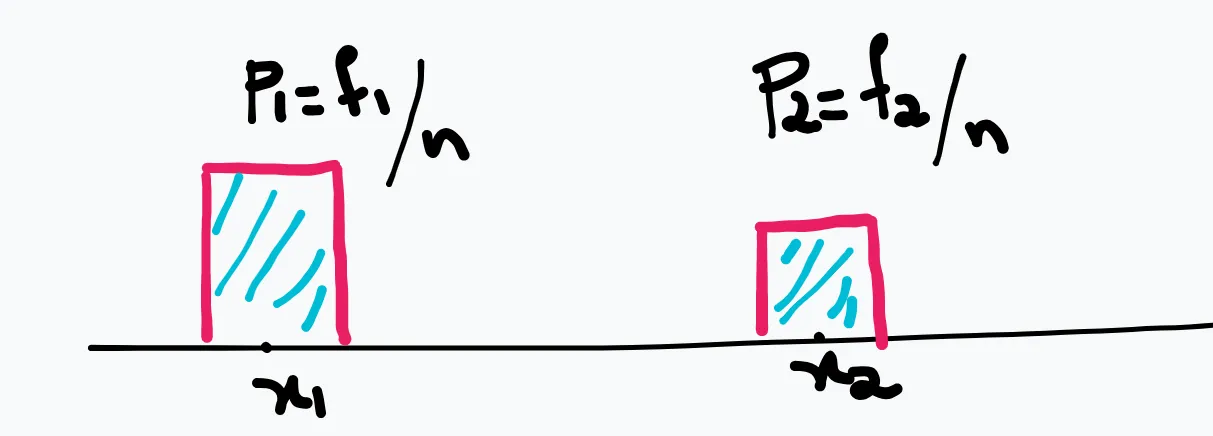
PDF is not a probability. It is a tool to P(a<x<b)=∫abf(x)dxevaluate probability, whereas PMF0<P(x)<1;∑p(x)=1 is probability.
density x width = probability
density = widthprob = 2δp1 = 2δnf1 = widthrelative.frequency
a x1 x2 x3 x4 b
P(a<X<b)=d1(x1−a)+d2(x2−x1)+d3(x3−x2)+...=∑i=abdi(xi−xi−1)
Approximate, di=f(xi) and wi=xi−xi−1
As w —> 0, ∫abf(x)(xi−xi−1)
If you have a function g(x)≥0 and ∫Rg(x)dx=a, then f(x)=ag(x) is a PDF and g(x) is kernel of PDF, a is normalising constant.
Cumulative Distribution Function
∫−∞af(x).dx=P(x≤a)=Fx(a)
Moment Generating Functions
E[g(x)]=discrete∑g(x)P(x)=∫g(x)f(x)dxcontiuous
If X is a Random Variable with f(x) as the Probability Density Function, then MGF is E[etx]=∫etxf(x)dx (continuous) =∑etxP(x)(discrete) =g(t)=∫(1+tx+tx2/2!+...)f(x).dx (Using Taylor Series of ex)
=∫f(x)dx+t∫xf(x)dx+t2/2!∫x2f(x)dx+...g(t)=1+tE[X]+t2/2!E[X2]+...g′(t)=E[X]+tE[X2]+t2/2!E[X3]+...
Therefore, g′(0)=E[X] and g′′(0)=E[X2], and V(X)=g′′(0)−(g′(0))2
Why do we need the moments?
I do not want to solve 4 integrations for finding the 4 properties of a distribution. I will solve 1 integration, namely E[etx] and then differentiate to obtain 4 moments. Therefore, these moments help in uniquely identifying the distribution.
Raw Moments vs Central Moments?Raw Moments: Subtract “0” from X
Central Moments: Subtract "μ" from X
Variance is the 2nd Central Moment and Skewness is the 3rd Central Moment Link
Cauchy Distributionf(x)=π11+x21, where −∞<x<∞
The real moments does not exist for the distribution. It is also called as t-distribution with 1 DOF
Sampling Distribution
Population: CMI ka Students
X = No. of books ordered by a student
We are interested in finding E[X]=μ
Define a Random Sample of size n: D = x1,x2,x3,...,xn, and xˉ=n1∑i=1nxi
Conduct this experiment many times, and plot the means. This’ll be your Sampling Distribution of the Sample Means.
Intention? Find μ
The sampling distribution gives a sense of how far sample mean is away from the hypothetical true mean. It helps in quantifying the uncertainty in the data. Also helps in comparing 2 different probability estimations.
We want to figure out the sampling distribution of the sample mean from single sample
Suppose X1,X2,X3,...,Xn are iid N(μ,σ2)
Xˉ=n1i=1∑nxi
We want to find MXˉ(t)MS(t) = E[ets] = E[et∑i=1nxi] = E[∏i=1netxi] = ∏(E[etxi]) = ∏(Mxi(t)) = ∏(etμ+2t2σ2) = ∏(etnμ+2t2nσ2)
Therefore, S∼N(nμ,nσ2)
We know, Xˉ=nS
So, MXˉ(t)=E[etXˉ]=E[etnS]=E[ents] = ∏(entnμ+2(nt)2nσ2)=∏(etμ+2nt2σ2)Xˉ∼N(μ,nσ2)
Central Limit Theorem
X1,X2,X3,...,Xn∼iidf(x), and f(x) is an appropriate probability function such that E[Xi]=μ and V[Xi]=σ2<∞
What is the distribution of Xˉ?
MXˉ(t)=E[etXˉ]=∏E[entXi]
Since, i.i.d, replace i with 1E[entX1]n
Find MGF of X1 and plug here
MX1(t)=E[etXi]=E[1+tX1+2t2X12+...]=E[1+tX1+2t2X12+O(t)], since t∼0=1+tμ+2t2E[X12]+O(t2)=1+tμ+2t2(σ2+μ2)+O(t2)
Therefore, MXˉ(t)=[MX1(nt)]n
RESULT
If X∼N(μ,σ2), then MX(t)=E[etX]=etμ+2tσ2
If X∼N(0,σ2), then MX(t)=E[etX]=e2t2σ2
If X∼N(0,1), then MX(t)=E[etX]=e2t2
Take Z=Xˉ−μ and MZ(t)=E[etZ]=E[1+tZ+2t2Z2+O(t3)]=1+tE[Z]+2t2E[Z2]+O(t3)=1+0+2t2nσ2+O(t3)
We know, (1+nx)n≈ex, when x is around 0, and n —> ∞
Therefore, 1+0+2t2nσ2+O(t3)≈e2t2nσ2
So, Z=Xˉ−μ≈N(0,nσ2), as n —> ∞σn(Xˉ−μ)≈N(0,1), as n —> ∞
Lindyberg-Levy’s CLT
Let X1,X2,X3,...,Xn∼iidf(x) with E[X1]=μ1 & V(X1)=σ2<∞Zn=σn(Xˉ−μ)≈N(0,1) as n —> ∞
Centralise first, for quick convergenceCLT fails in Cauchy, but Cauchy not seen in real-life
Bernoulli
Suppose X1,X2,X3,...,Xn∼iidBernoulli(p),0<p<1, where E[Xi]=p,V[Xi]=p(1−p)<∞Xˉ=nS=p^, where s is the number of successes.
E[p^]=E[n1∑iXi]=n1(np)=pV[p^]=V[n1∑iXi]=n21(np(1−p))=np(1−p)
By CLT, p(1−p)n(p^−p)→N(0,1) as n —> ∞
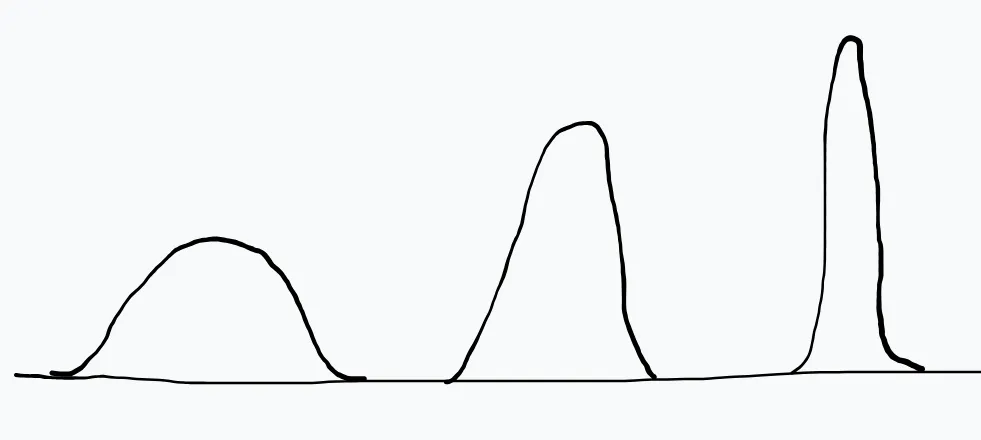
For large sample, sampling distribution of sample population approximately follows Gaussian Distribution.
Gamma
Despite the fact that Xˉ of Gamma Random Variables is Gamma, the CLT still holds. Since, after a certain n, Gamma starts to behave as Gaussian.
Serious Criticism of TB statistical inference relying on CLT is it requires large sample size
Solution? Bootstrap Statistics
Important Results
Y∼N(μ,σ2), then Z=σY−μ∼N(0,1) and Z2∼χ(1)2
If Z1,Z2,...,Zn∼N(0,1), then S=∑i=1nZi2∼χ(n)2
X1,X2,....,Xn∼N(μ,σ2), then 1. Zn=σ(n)(Xˉ−μ)∼N(0,1) 2. U=σ2(n−1)s2∼χ(n−1)2, where s2=n−11∑i=1n(xi−xˉ)2 3. Zn & U are independent of each other 4. sn(xˉ−μ)∼tn−1
In part(4) of 3, if you replace σ with estimated σ, then the distribution follows t and moves away from normal.
Statistical Inference
DatasetX1,X2,...,Xn∼iidFθ(x); θ is an unknown population parameter.
Based on this dataset, make an educated guess about θ
In Data Sciences, people are majorly interested in:
I : Predictive Modelling
II : Statistical Inference
Point Estimation / Training in ML
Testing of Hypotheses
Confidence Interval
Estimator
T(n)=T(X1,X2,...,Xn
For example, θ^=argmaxHL(θ∣D):MLE
Any process you come up with to make an educated guess about θT(n)=T(X1,X2,...,Xn∼Gθ(t), which is the CDF of sampling distribution of Tn
If E[Tn]=θ, then we call Tn as an Unbiased Estimator
If E[Tn]=θ+δ or θδ, then we call Tn as an Biased Estimator
Problem
θ is unknown
We need to learn or estimate it from dataset
More Examples of Estimators
T=Xˉ=n1∑i=1nXi | Sample mean is an estimator of population mean E[X]=μ
T=S2=n−11∑i=1n(Xi−Xˉ)2 | Sample variance which estimates the population variance V[X]=σ2
T=Sn2=n1∑i=1n(Xi−Xˉ)2 | Sample variance which estimates the sample variance
Which is better among (2) & (3)
Competing Estimators
If T1 and T2 are two competing estimators of θ, which one should we prefer?
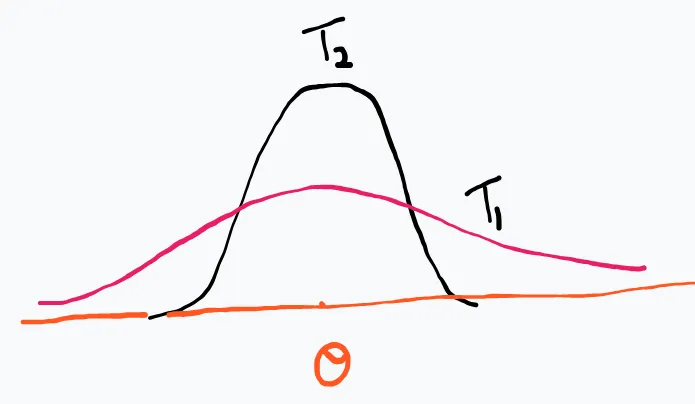
We compare their sampling distributions.
If this is the case, we clearly prefer T2, as it’s more concentrated around θ
We compare:
P(θ−δ<T1<θ+δ)<P(θ−δ<T2<θ+δ)
Which corresponds to comparing the probability mass under the sampling distributions:
∫θ−δθ+δgθ(t1)dt1vs∫θ−δθ+δhθ(t2)dt2
But — we don’t know the sampling distributions of T1 and T2 in practice (???)
Mean Squared Error (MSE) as a Criterion
Instead, we work with something more concrete: Mean Squared Error (MSE)MSE=E[(T−θ)2]
If MSE(T1)<MSE(T2), we know T1 has, on average, less error, and so we prefer T1 over T2.
We can decompose MSE as follows:
E[(T−θ)2]=E[(T−E[T]+E[T]−θ)2]
Expanding this:
E[(T−E[T])2]+(E[T]−θ)2=Var(T)+(Bias(T))2=Var(T)+(Bias(T))2
This is the bias-variance tradeoff.
Even if the bias of T2 is more, if its variance is very small, we might still choose it.
This tradeoff is captured in the MSE decomposition.
Concrete Example
Let X1,X2,…,Xn∼N(μ,σ2)
Two estimators for population variance σ2:
Sn2=n1∑i=1n(Xi−Xˉ)2
S2=n−11∑i=1n(Xi−Xˉ)2
Consider,
σ2(n−1)S2∼χn−12E[σ2(n−1)S2]=n−1⇒E[S2]=σ2
So, S2 is an unbiased estimator of σ2.
Var(σ2(n−1)S2)=2(n−1)⇒Var(S2)=n−12σ4
Since the bias is 0:
MSE(S2)=Var(S2)=n−12σ4
So, S and Xˉ are sufficient statistics of D because ID=IS
We want to calculate the information of Xˉ and show that it is sufficient.
Theorem by Fischer:
Let T=f(S) be a one-one function.
Then, T is also a sufficient statistic if S is a sufficient statistic.
Imagine you have 100 thermometers measuring the same temperature (with Poisson noise). Each gives you one reading. But if someone tells you the total sum or average, you can figure out the temperature just as well as if you had all 100 readings. So the sum/average is all you need — it’s sufficient. And you get the same precision in your estimate (same Fisher information).
MVUE & Cramer-Rao Inequality
Suppose that T=T(x) is an unbiased estimator for real-valued parametric function T(θ), that is E[T]=T(θ)∀θ∈H
Assume dθd(T(θ))=T′(θ) exists and finite,
Then,
V(T)≥nEθ[∂θ∂logfθ(xi)]2[T′(θ)]2=I(θ)[T′(θ)]2
Test 1Test Statistic: xˉ
Reject Null Hypothesis, if xˉ>c1
Test 2Test Statistic: sample variance(s2)
Reject H0 if sample variance(s2) >c2
Test 3Test Statistic: Sample Median(m)
Reject H0: if m>c3
Pr(Type I error)≤α
=> Pr(Reject Null Hypothesis, When null is true)≤α
==> Pr(T>c∣H0is True)≤α
**Under H0
Simulate D∗←x1∗,x2∗,...xn∗∼Poisson(λ0)
Calculate xˉ∗,s2∗,m∗
Repeat Step 1 and 2 M times
Draw a histogram of x1∗,x2∗,...xn∗ | s12∗,s22∗,...sn2∗, etc… and find c on the histogram such that the area under the curve to the right of c in the distribution is less than α
We now would like to do intra-test comparison to figure out the test with great power
Type-II Error
Pr(Type II error)=Pr(Not Reject H_0 When H_1 is true)
Power = 1 - Type(II)
Joint, Marginal Distributions
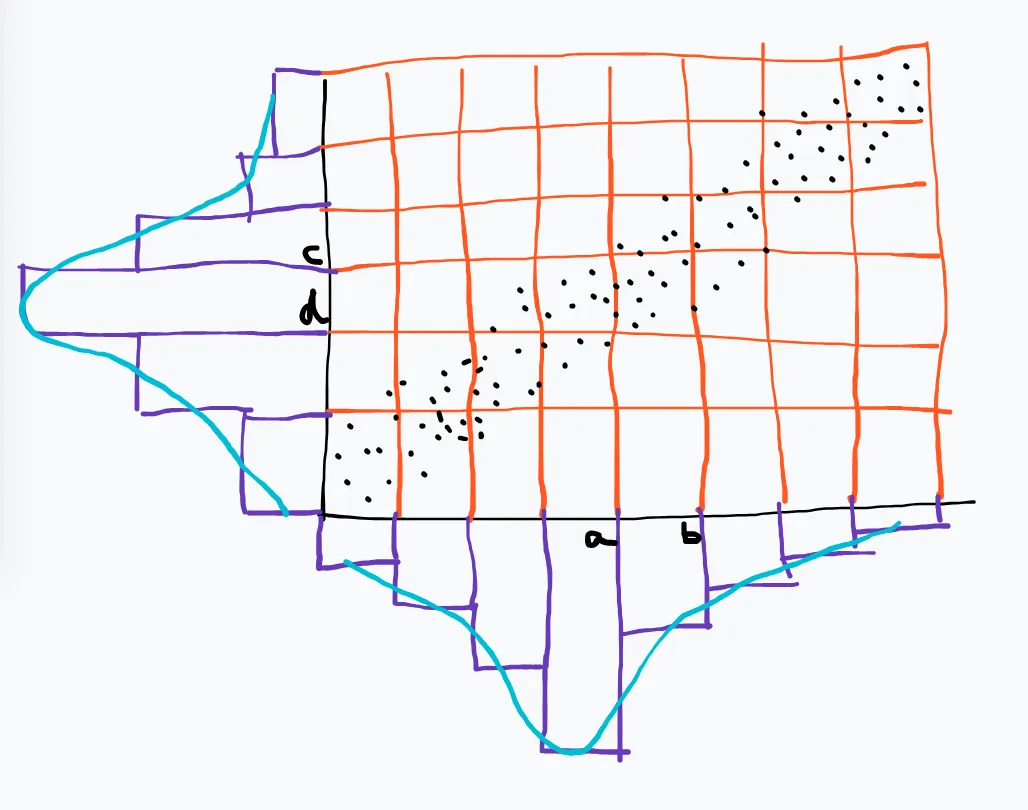
fi=#(a<xi<b & c<yi<d)nfi=rf(a<xi<b & c<yi<d)rfd=Area of the Boxrfrfd=(b−a)(d−c)rf=ΔxΔyrfJoint Probability Density=AreaProbability
f(x,y) is the joint PDF such that
(1)f(x,y)≥0∀x,y∈R2(2)∫∫R2f(x,y)dxdy=1
f(x) is the marginal PDF Distribution of X where
(1)f(x)=∫yf(x,y)dy(2)f(y)=∫xf(x,y)dx
How do you explain the fitter line on a scatter plot from a probability perspective?
Conditional Expectation of ‘y’ given ‘x’
The line formed by joining the expectations of conditional distributions of y given x is called the regression line/function or prediction line/function
If Joint PDF is bi-variate or multi-variate gaussian distribution, then the resulting regression function will be a straight line
α+βxE[y∣x]=∫yf(y∣x)dy
If (x,y) are assumed to be normal, then y can be α+βx+ϵ AKA straight line.
Correlation
The Degree of Linear Association
The Correlation between x and y depicting a upper-half of a semi-circle function will be close to zero, since correlation can only talk about the linear relationship between 2 variables.