Building an Indian-Accented English TTS
I was recently tasked with building a TTS (Text-to-Speech) model for Indian-Accented English. Prior to this, my knowledge of TTS models was limited to late-night conversations with my friend, who’s a TTS Researcher.
I had a decent grounding in the basics of Generative AI, so I got to work. I picked up the Neural Speech Models survey paper, printed it and read through it over a few days, fueled by many cups of lemon tea.
Once I got a lay of the land, I went digging through the interwebs to find an English TTS model that sounded natural, expressive, and operated with conversational-level latency. I shortlisted a few, but the Orpheus Model by Canopy Labs stood out to me.
I began studying their blog, GitHub READMEs, issues, forum posts—essentially everything I could get my hands on to gain context.
After a conversation with another friend, I started diving deeper into Speech-LLMs and audio codecs. (To be honest, I don’t fully understand their inner workings yet, but I’ve started forming a mental map.)
Attempt 1: Finetuning on IndicTTS
I downloaded the IndicTTS Dataset, sifted through various speakers, and chose a Bengali Female voice. It sounded less monotonic compared to others. I collated 300 samples of 5 seconds each (as recommended by the Orpheus folks) and fine-tuned the model using LoRA:
My goal was to fine-tune just enough to teach it “Indian-ness”—but not so much that it would lose expressivity and instead learn the monotonicity of the dataset.
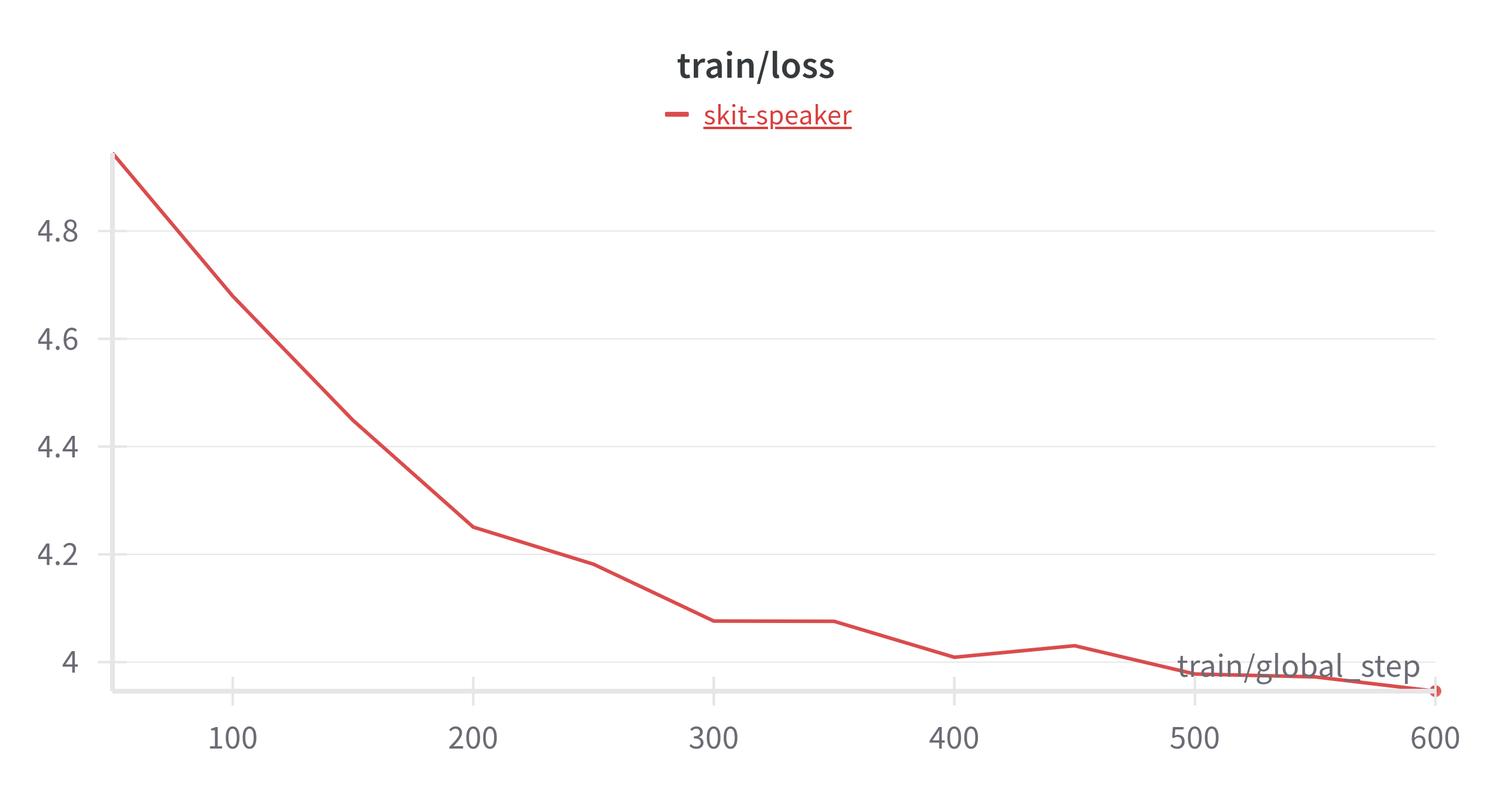
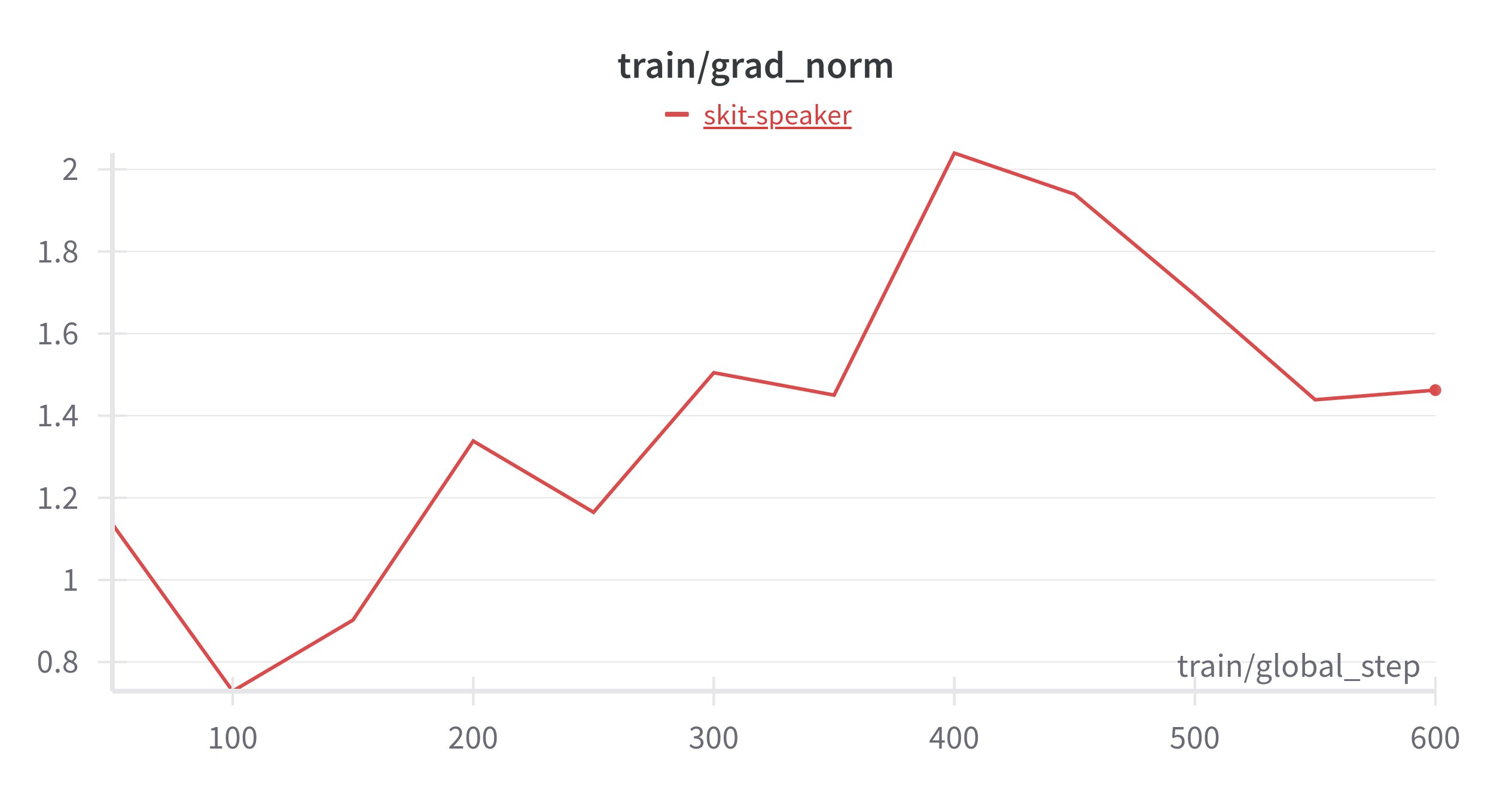
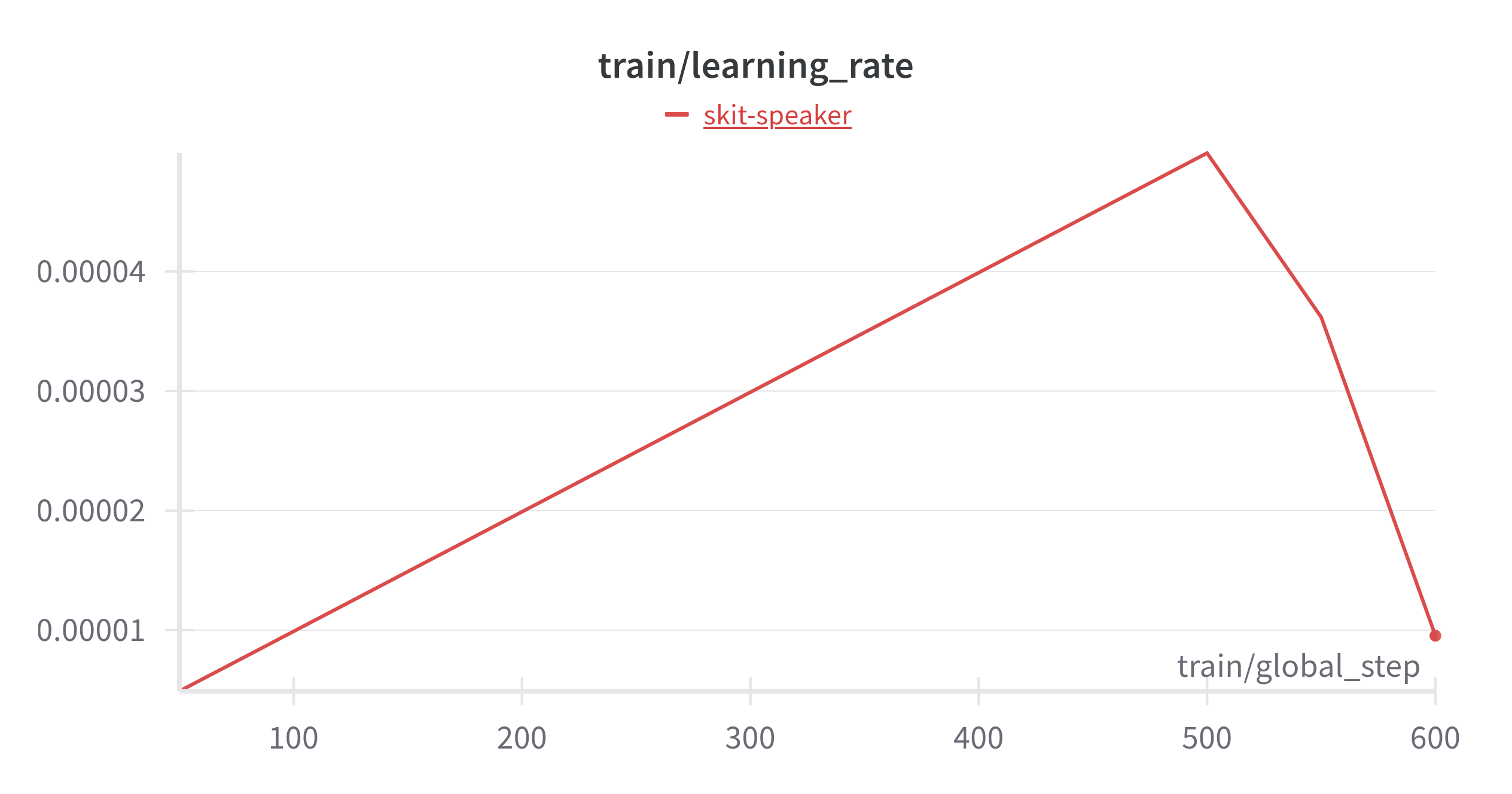
WandB
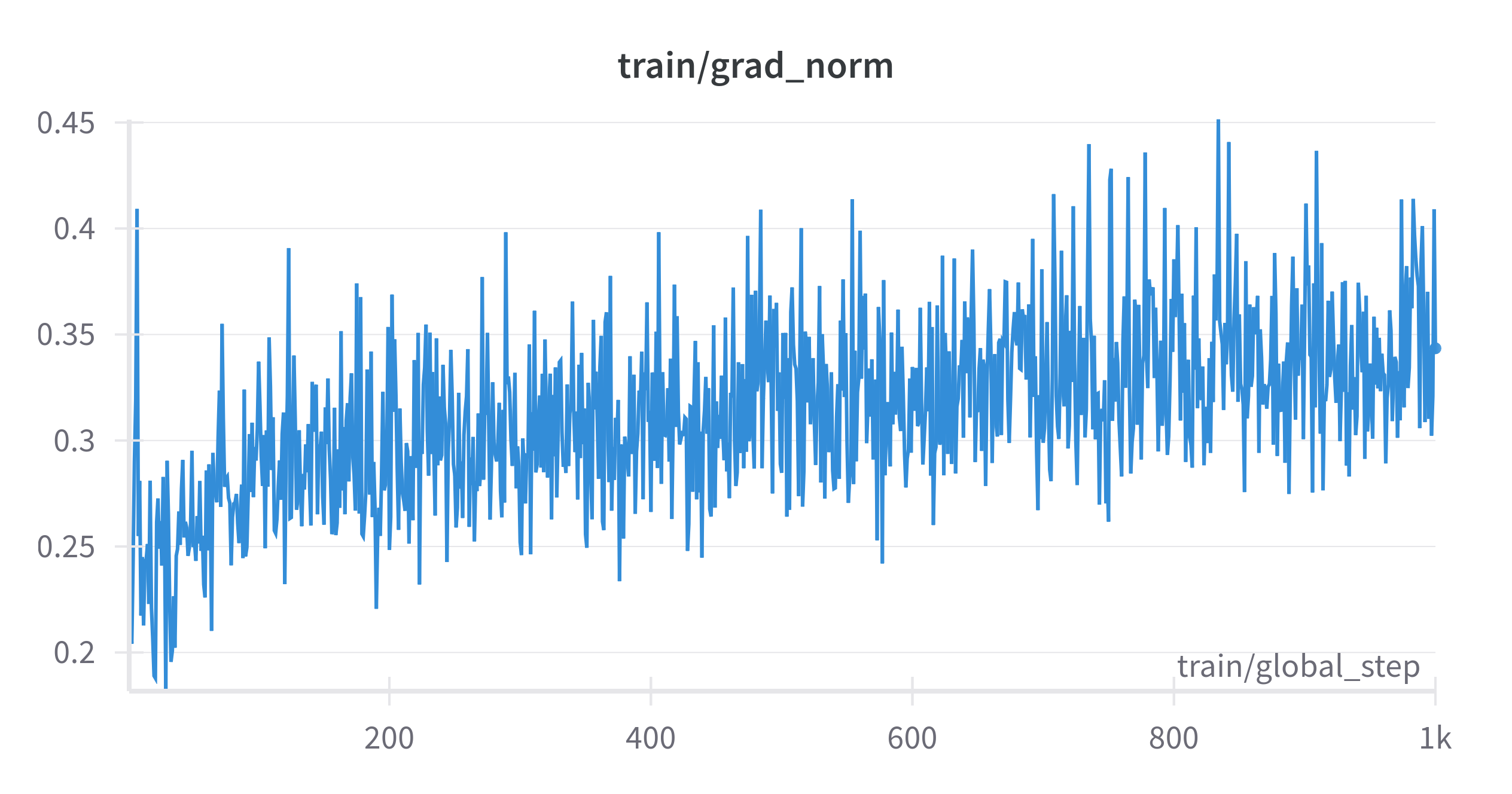
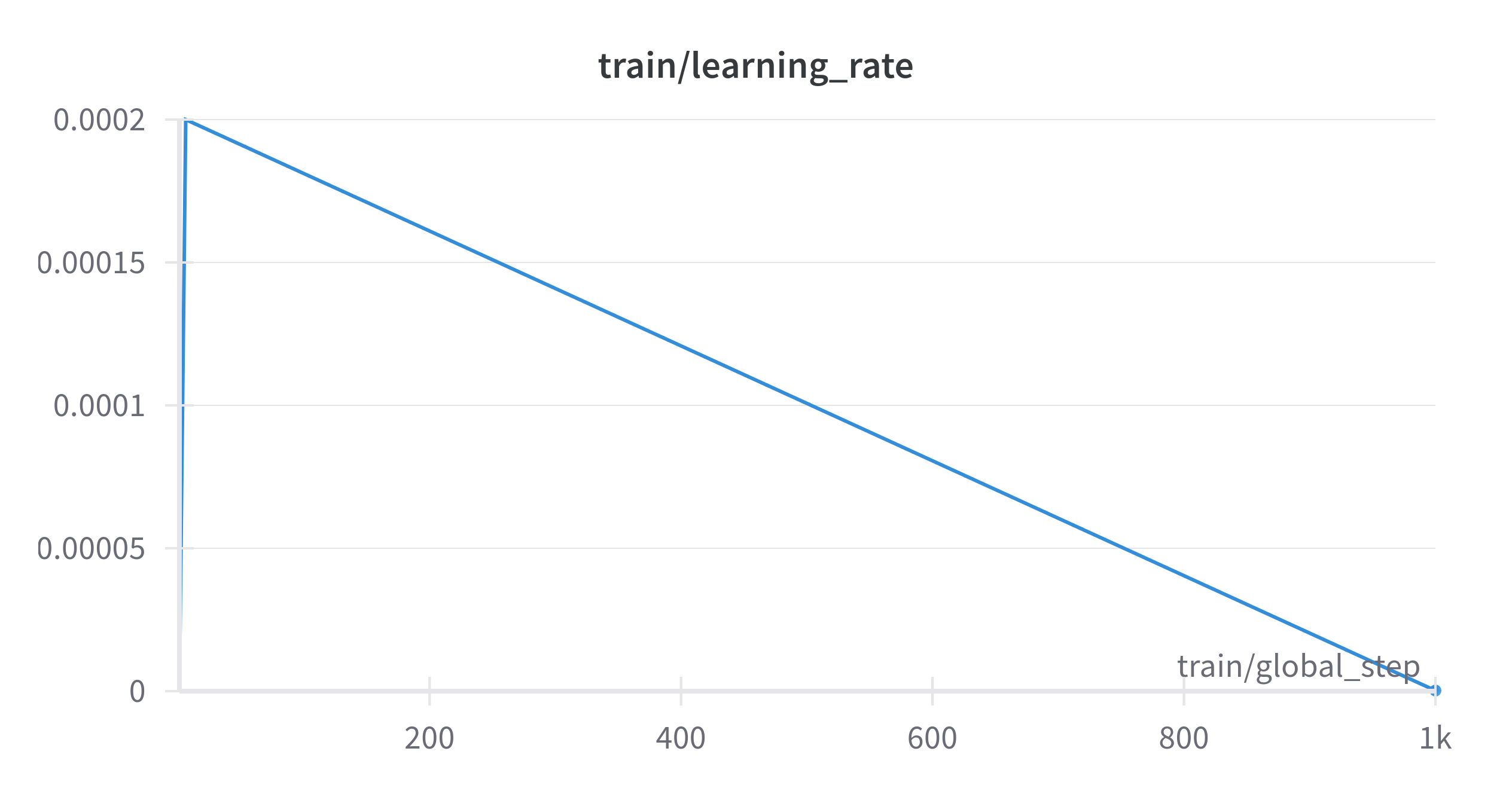
The graphs aren’t good news!
Need
I need to fix 2 things, for it to be usable:
- A better dataset that has more expressive samples, as made evident by the samples.
- Fix the training dynamics which are not good, as evident by the WandB graphs.
Fixing Two Core Issues
1. A Better Dataset
I needed a more diverse and expressive dataset. Once I had that, part one of the problem was solved. I got it.
2. Fixing Training Dynamics
The next challenge was training dynamics. My training curves were:
- Extremely noisy
- Not smooth at all
- Unstable, with sharp spikes
Hypotheses for What Went Wrong:
- Learning rate was too high for LoRA on a small dataset
- Almost no warmup
- Starting at the full
2e-4learning rate right from the first step (on gradients that only saw tens of examples) often caused gradient explosions
- Starting at the full
- A high LoRA rank for such a small and specific task
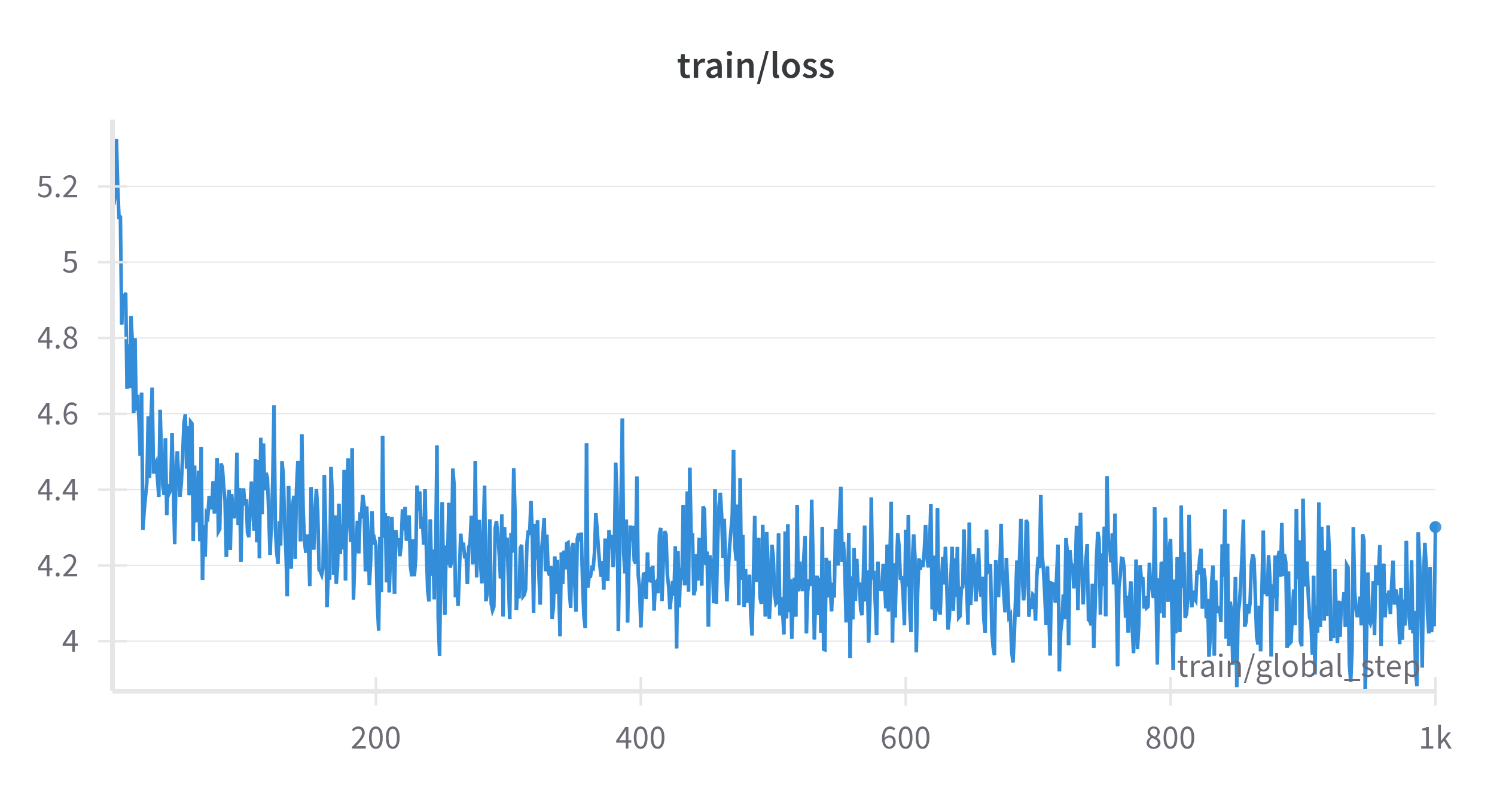
Attempt 2: Changes I Made:
-
Lowered peak LR to
5e-5to1e-4
→ Helped reduce overshooting and allowed smoother convergence on small data -
Longer warmup (~500–1000 steps)
→ Gave the LoRA weights time to “find the valley” instead of jumping in cold -
Gradient clipping (
norm = 1.0)
→ Prevented runaway gradients that were causing sharp training spikes -
Reduced LoRA α or rank
→ Lower capacity adapters = less over-correction on every mini-batch -
Used a better LR scheduler
→ Switched to a cosine scheduler with warmup, which allowed for smoother learning rate decay
WANDB graphs