This document provides a comprehensive overview of Generative Adversarial Networks (GANs), their mathematical foundations, and various implementations. It covers the motivation behind GANs, the process of generative modeling, and different types of GAN architectures including DC-GAN, Conditional GAN, and Wasserstein GAN.
This is a live document, and I will keep updating it as I implement more GANs.
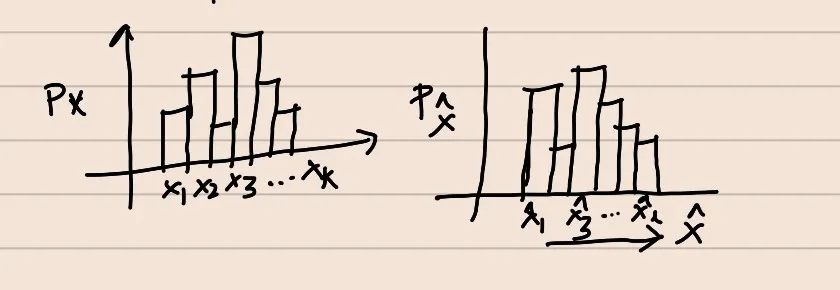
I’ve been given a sample data which is sampled i.i.d from a population. I intend to learn the parameters of the probability distribution of the population and then, sample at will.
Goal
So, I can decompose my goal into:
Estimate the probability distribution of the population Pdata
Learn to sample from that estimate
Initial Plan
Given,
x1,x2,x3,...,xn∼Pdata (unknown distribution)
I’ll construct a Pgen and push Pgen towards Pdata
From hereon, I will refer Pdata as PX and Pgen as Pθ
Also, P refers to Distribution Function and P refers to Probability Density Function
Assumption: Hereon, we shall solely use P with the assumption that the Distribution Functions we’re dealing with have well-behaved Density Functions. [To make the calculations and math a little more easier]
Density Function is not a probability. It is a tool to evaluate probability
The 3-step Process of Generative Modelling
Assume a parametric family on PX denoted by Pθ
This Pθ is represented by Neural Networks
Define & Compute a divergence metric between the Pθ and PX
We don’t know Pθ and PX though?
Solve an optimisation problem over the parameters of Pθ to minimise the above divergence metric
Chalo, Assume you’ll somehow be able to compute the divergence metric between probability distributions that you don’t even know, and also optimise them, how will you begin to think about how you’ll sample from the estimated probability distribution?
The Push-Forward Methods
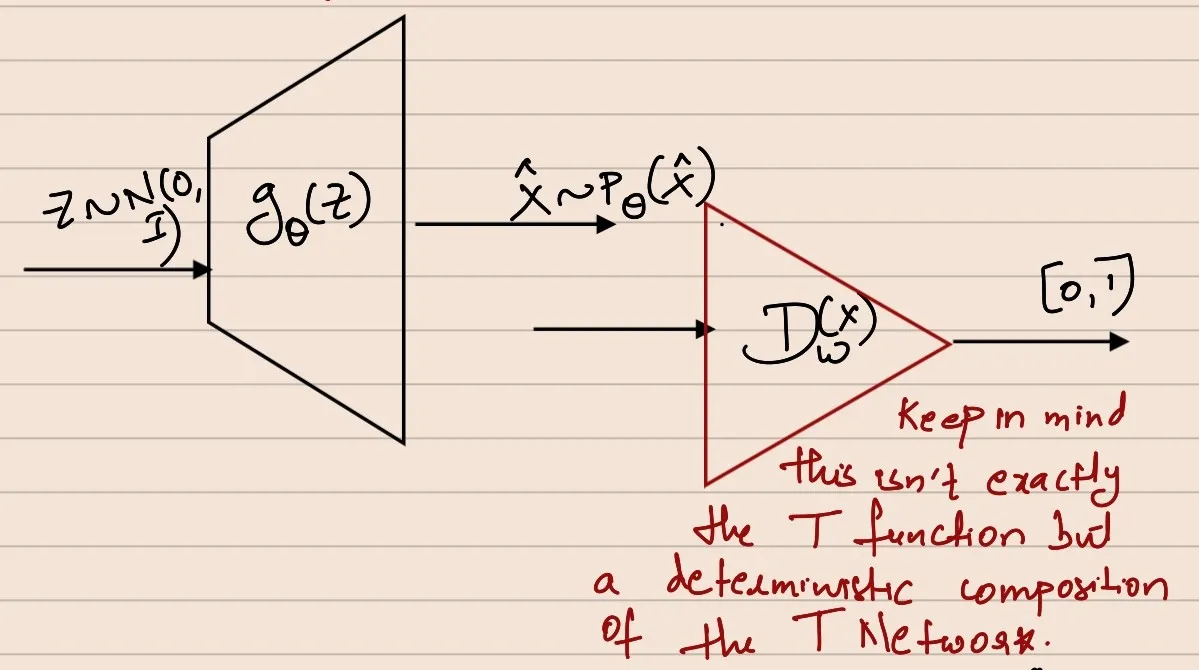
Consider some arbitrary but known distribution Z∼N(0,I) and gθ(z):Z→X, then X~=gθ(Z) has a different distribution than that of Z. So, if you end up constructing a gθ that will produce a X~ that has the same distribution or close to that of PX, we are in the game.
_Add the generator diagram here
Impending Questions
How to compute the divergence metric without knowing Pθ and PX?
What should be the choice of the divergence metric D?
How to choose the gθ(z), in turn, Pθ?
How to solve the optimisation problem of minimising the divergence metric?
Variational Divergence Minimisation
Define DIVERGENCE between distributions
f-divergence
Given 2 probability distribution functions with the corresponding density functions denoted by PX & Pθ, the f-divergence between them is defined as follows:
Df(PX∣∣Pθ)=∫χPθ(x)f(Pθ(x)PX(x))
f(u):R+→R, convex, left-semi continuous, and f(1)=0χ:space on which thePX&Pθare supported
Df(PX∣∣Pθ)Forward KL=Reverse KLDf(Pθ∣∣PX) | KL-Divergence is not symmetric
Difference choices of f functions result in different divergence metric with their own properties; which necessitates the need to look at swathes of divergence metrics.
JS Divergence: f(u)=21(ulogu−(u+1)log(2u+1)) | Used Famously in GAN
Total Variational Distance: f(u)=21∣u−1∣
Algorithm for f-divergence minimization
Objective: Algorithm to minimise Df between PX and Pθ, without knowing neither, but having samples from both.
Samples from PX - Dataset D
Samples from Pθ - Outputs of gθ(z) for different z
But, without knowing Pθ(x) and PX(x), solving a high-dimensional integral is infeasible.
Key Idea: Integrals involving density functions can be approximated using samples from the distribution.
The Law of Unconcisious Statistican
Suppose we wanted to compute,
I=∫χh(x)PX(x)dx
where h(x) is a function and PX(x) is the density function.
Also, suppose that we have samples drawn i.i.d from PX
x1,x2,x3,....,xn∼i.i.dPX
I=EPX[hx]
Law of Large Numbersxi∼i.i.dPXn→∞limn1i=1∑nh(xi)=EPX[h(x)]
_If the terms of the f-divergence can be expressed in terms of expectation of functions with respect to PX and Pθ, then one can compute and optimise them_
**Expressing Df in terms of Expectations over PX and Pθ
Df(PX∣∣Pθ)=∫χPθ(x)f(Pθ(x)PX(x)) <--- Even though this expression looks eerily similar to the integral form of the expectation, you cannot directly rewrite that expression in terms of expectation precisely because of the arguments of f. They aren’t simply “x”, but instead are the ratio of probability density functions.
Therefore, we somehow have to decouple the ratio of PDFs from ‘f’
SLIGHT DETOUR
Convex Conjugate
If f(u) is a convex function, then there exists a conjugate function
f∗(t):=u∈dom(f)suput−f(u)
Essentially, we are lower-bounding f(u) at every point t.
because the space of functions T that we are optimising over may not contain the optimal T∗(x), that is the solution for the inner optimisation problem.
But we are relegated to solve θ∗=argminθ[lower bound on Df] and that’s the best we can do.
=argminθ[T(X)sup{EPXT(X)−EPθf∗(T(X))}]
Calculating the supremum with respect to a class of functions T(X)∈T cannot be done analytically (?), since it is an optimisation procedure over a space of non-trivial functions.
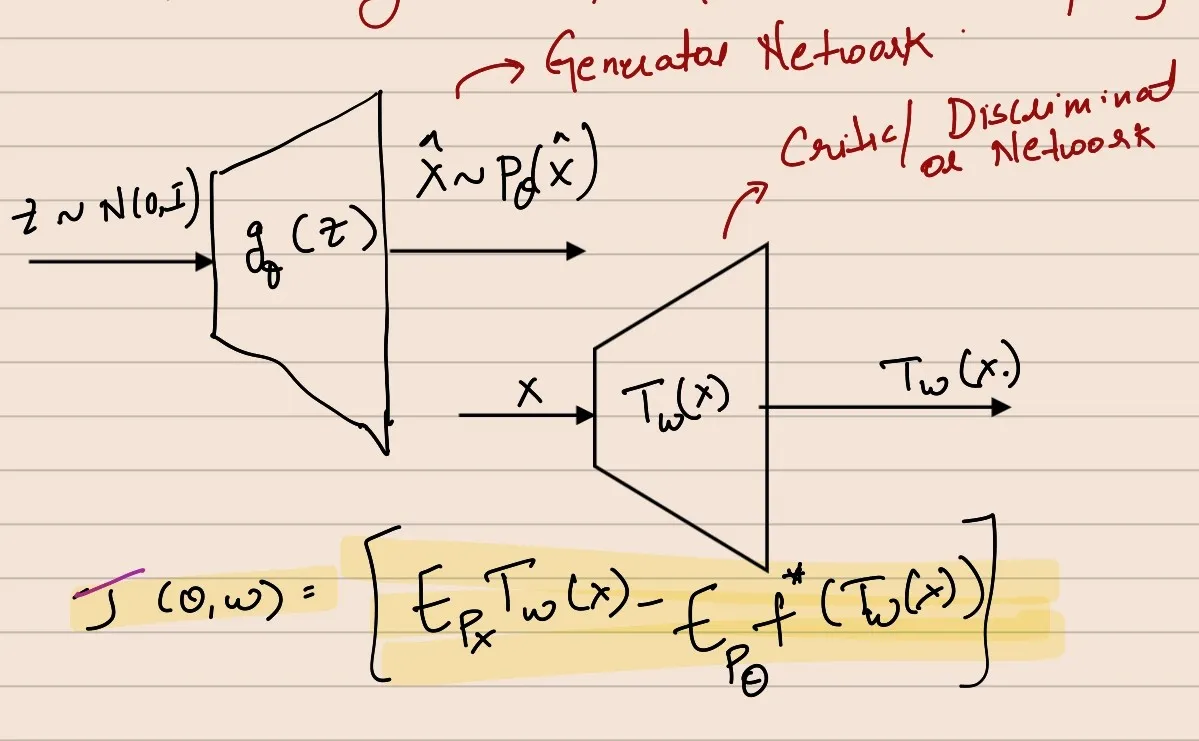
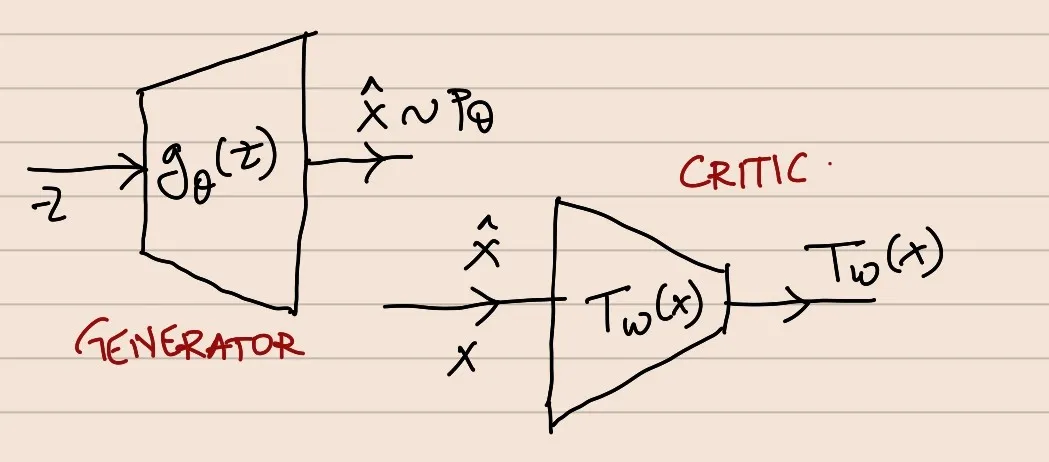
In practice, we represent T via neural networks: Tw(X), where w are the parameters of the neural network.
This, essentially, is the Blueprint for Adversial Training
Any saddle point optimisation problem is also a adversial optimisation problem.
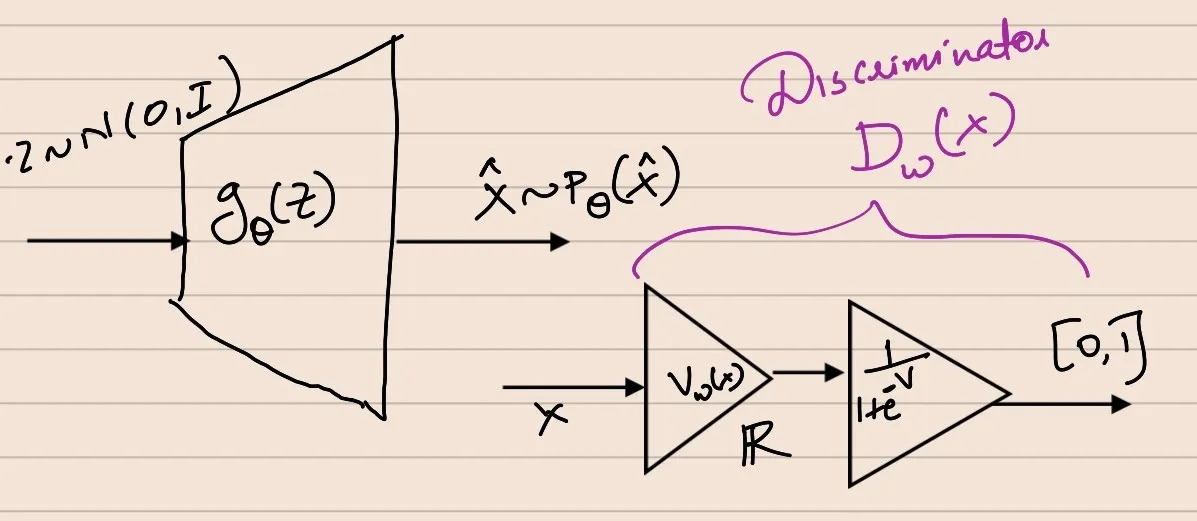
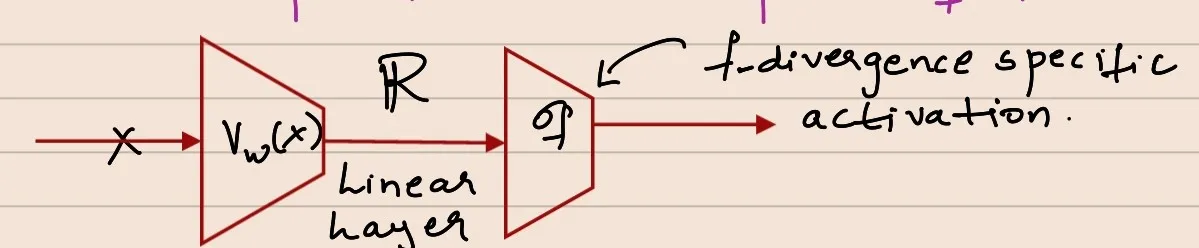
We know, by construction, T():X→dom(f∗) ---> Depending on the choice of f∗, we need to tweak the T network so that the range of T network corresponds to domain of f∗ ---> In practice, we do this by representing Tw(X) as σf(Vw(X)), where σf is a f-divergence specific activation
Vw(X):X→R, σf(v):R→domf∗
This means the T network that we’ll approximate using neural networks is represented as a composition of 2 functions.
The Discriminator as the composition of 2 functions will go here
J(θ,w)=[EPXσfVw(x)−EPθf∗(σfVw(x))]
Generative Adversial Networks
A Special Case of VDM Algorithms
The choice of f-divergence: ulogu−(u+1)log(u+1)Awfully similar to JS Div.
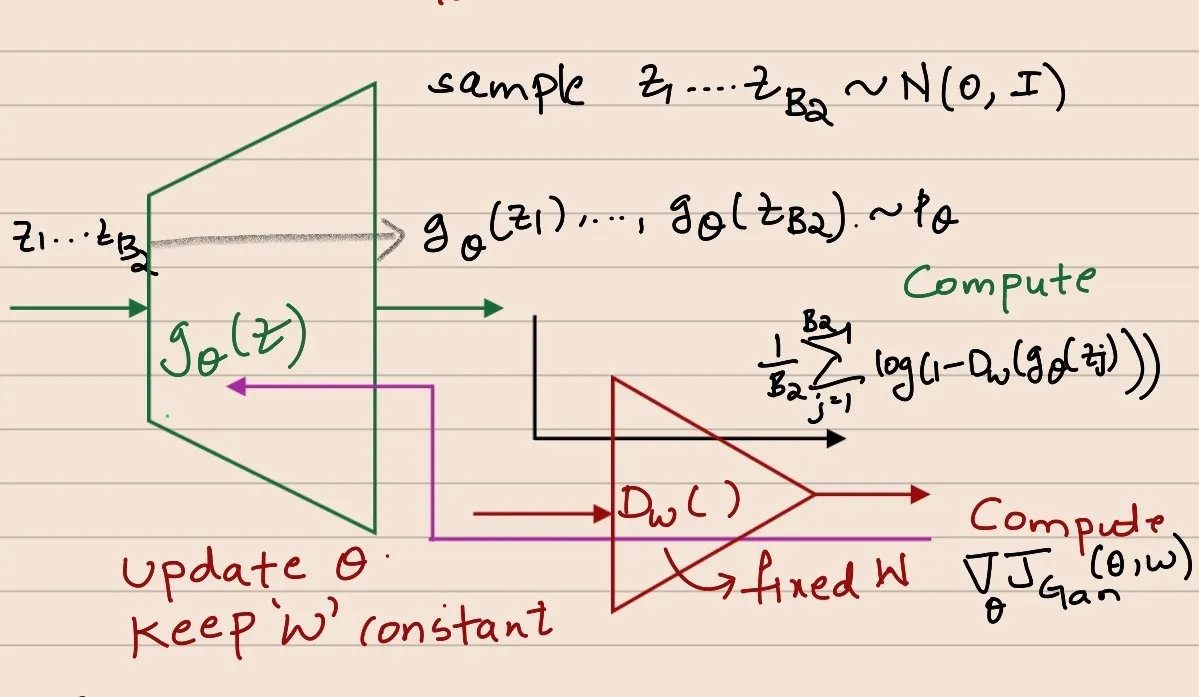
While training the discriminator the parameters of the generator network are kept constant.
Sample z1,z2,...,zB2∼i.i.dN(0,I)
Pass them through gθ(z) to obtain gθ(z1),gθ(z2),...,gθ(zB2)
Pass these through Dw(.) and obtain the 2nd term in loss
Get x1,x2,...,xB1∼Px
Pass these through Dw(.) and get the 1st term in loss
TOTAL LOSS = TERM 1 + TERM 2
This is how the gradient ascent is implemented for the discriminator network.
Generator N/W:
θ∗=argminθB11i=1∑B1logDw(xi)Independent of θ+B21j=1∑B2log1−Dw(gθ(zj))θt+1←θt+α2∇θJ(θ,w)
While training the generator the parameters of the discriminator network are kept constant.
GAN as Classifier-Guided Generative Sampler
D={x1,x2,...,xn}∼i.i.dPX
Goal:Pθ(x^) to be close to PX
Suppose there’s a binary classifier,
Dw(X)={1 if x∼PX0 if x∼Pθ
Dw(X) is a binary classifier between the samples of PX and Pθ
Question: Can Dw(X) be used to make PX and Pθ closer?
Answer: Yes. Tweak θ till the classifier fails to distinguish between the samples of PX and Pθ
However, Failure of the classifier need not imply PX=Pθ (A counter example supporting this statement can be easily formed)
Solution: Keep altering the classifier along with the data (pretty intuitive)
Natural Question: What if the data clusters just cycles around 2 positions? We may get stuck!!!
This is Possible. It’s called MODE COLLAPSE, a failure mode in GANs
Formulation
Suppose, Dw:X→[0,1]
Let Dw(X) represent the likelihood of sample X coming from PX
The objective is to maximise the log-likelihood of X coming from PX
w∗=argmaxw[EPXlogDw(x)]
Maximising the likelihood of X∼PX
Classifier should also maximise the likelihood of X^ not coming from PX, when X^∼Pθ
Same as the loss-function we’ve obtained in the VDM.
The Objective for The Generator
It’s job is to make the classifier “fail”
Invert the optimisation for the classifier
θ∗=argminθJ(θ,w)θ∗,w∗=argminθwmaxJ(θ,w)
This classifier-guided interpretation of GAN is not generalizable across other f-divergences.
Because, there’s no guarantee that the T function we use to bound the f-div has the interpretation that T-function is a classifier. Only with this particular choice of f-divergence do we have that interpretation.
Deep-Convolutional GAN
Typically, in a GAN, Z∈Rk,X∈Rd,k<<d
In a DC-GAN, Upconvolution (or transpose convolutional) layers are used in the generator.
In DC-GAN, data is images
Implementation of DC-GAN
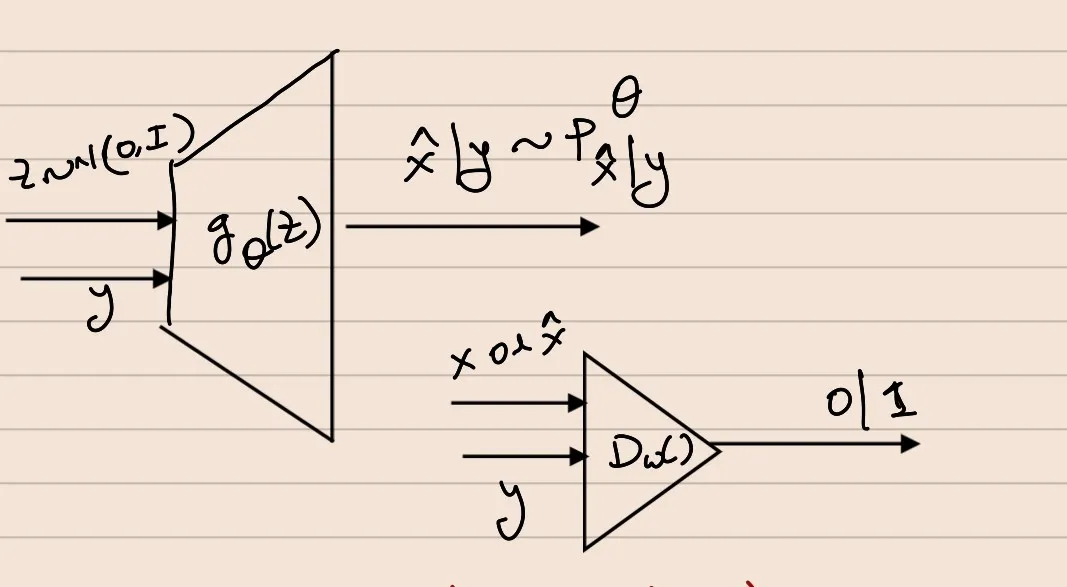
Conditional GAN
Data D: {(x1,y1),(x2,y2),...,(xn,yn)}∼i.i.dPXYExample:X : Images, Y : class-label / textual embedding
Objective: Sample from conditional distribution PX∣Y instead of PX (Naive GAN)
Solution: Estimate PX∣Y and make Pθ approach PX∣Y∀y
Modify the generator & discriminator to operate on the samples of conditional distribution.
The saddle point optimisation problem is difficult
Any f-divergence minimisation leads to unstable training
Question: What makes GAN training difficult and unstable?
Manifold Hypothesis
The data we observe in the wild reside in a very low-dimensional manifold in the ambient space (Rd)
Examplepixel011100
Consider this 5 x 5 image with Pij=1 if toss is heads & vice-versa.
The likelihood that an image generated by the above process resembles a real-world image is very low.
Therefore, it can be posited that real data exists on a lower dimensional manifolds.
Consequently, the supports of PX and Pθ will not be aligned with a very high probability.
It can be shown that a Perfect Discriminator can be learned when the supports of PX and Pθ are not aligned.
==> The GAN Training Saturates: Perfect Discriminator Theorem
For a perfect discriminator, the gradients flowing to generator nullify. Alternatively, it can be said that the lower bound on the loss is not tight, therefore minimising it would not make sense.
When we have a perfect discriminator ---> the Df(Px∣∣Pθ) becomes independent of θ
---> this causes saturation ---> Since, the gradients won’t flow to the generator, you wouldn’t be able to tweak the θ to make the generated data align with real data, effectively.
1 Empirical Solution is to not train them equally.
1 Principled Solution is to use a softer divergence metric that does not saturate when the manifolds of the supports of PX and Pθ do not align.
Wasserstein Metric [Optimal Transport]
Idea: We will show that the Wasserstein metric will not saturate and won’t become independent of generator’s metrics, despite the manifold of supports not aligning.
Given 2 distributions, PX & Pθ
W(PX∣∣Pθ)=λ∈Π(X,X^)minEx,x^∼λ∣∣x−x^∣∣2
λ:joint distribution between PX,PX^Π(X,X^): All possible joint distributions such that ∫xΠ(x,x^)dx=Px^ & ∫x^Π(x,x^)dx^=Px
Example: Suppose PX and PX^ are two 1-d discrete PMF.
The mass in PX can be redistributed such that PX transforms into PX^
A redistribution scheme can be represented as a joint distribution between PX and PX^
The above objective is very similar to GANs. Thus, the above method of minimising the wasserstein metric is called W-GAN.
Tw(X) has to be made 1-Lipschitz ---> How to achieve this is a research topic in itself
---> 1 Practical way to achieve this ---> Normalise the weights of Tw such that ∣∣w∣∣2=1 after each gradient step.
CONCLUSION: It is observed that training W-GAN is more stable compared to that of Naive GAN.
Implementation of WGAN
Inversion with GAN
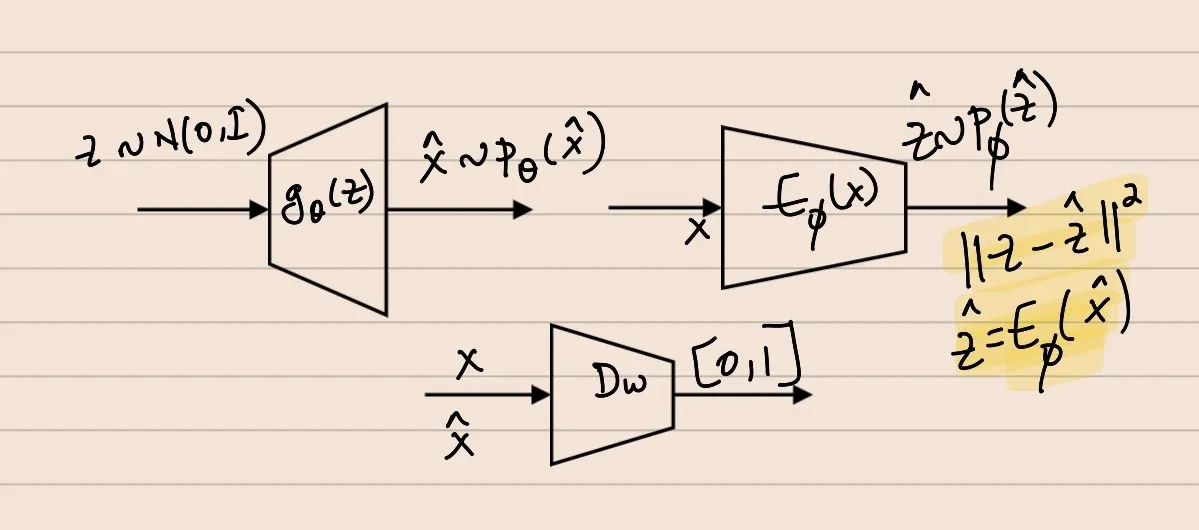
A trained GAN is a function Z→X. Suppose one is interested in inversion of the above function,i.e, given xi∼Px, find the corresponding Z ---> zi:gθ(zi)=xi
Question: How to modify a GAN such that the inverse is possible?
First off, why is it worthy of our attention?
Feature Extraction: Given a dataset obtain GAN-inverted vectors and use them as features for data. They, then, can be used for downstream tasks.
Data Manipulation & Editing: Suppose xi∼Px needs to be edited. First, obtain xi=gθ∗(zi) via inversion. Then, zedit=fedit(zi) & xedit=gθ∗(zedit)
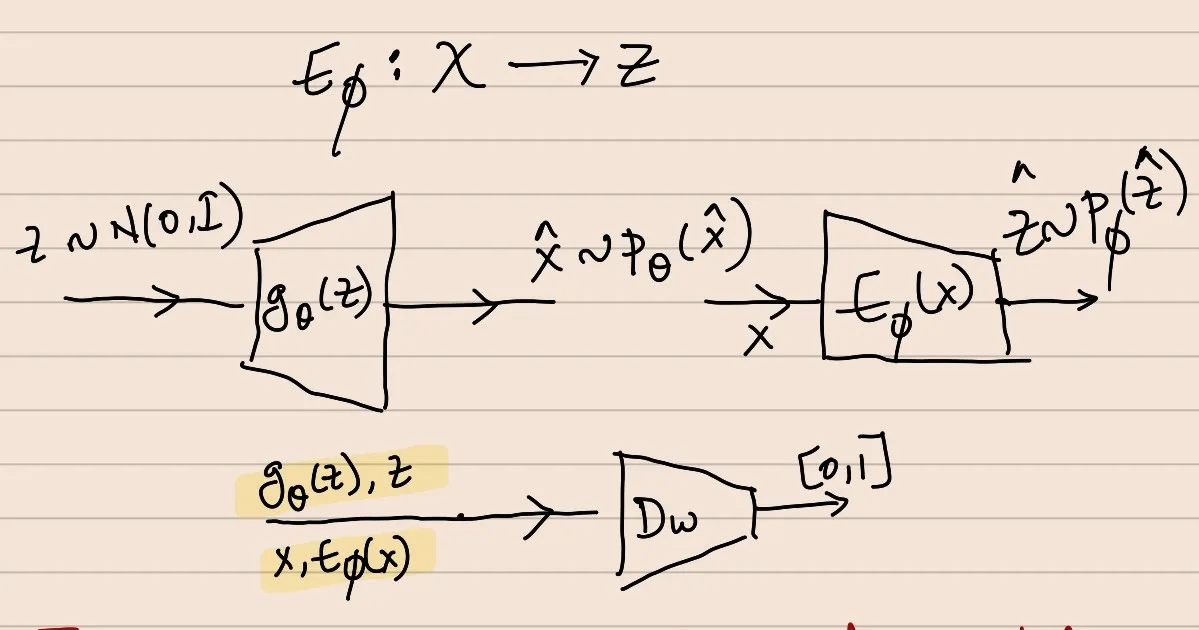
Approach 1: Bi-Directional GAN
In a Naive-GAN,
gθ(z):Z→XDw(x):X→[0,1]
In Bi-GAN, in addition to gθ(z) & Dw(x), there is another function called the Encoder or the Invertor network ---> Eϕ:χ→Z
In Bi-GAN, the Dw() is designed to classify between the data tuples of the form [X,Eϕ(X)] and [gθ(Z),Z], where X∼PX, Eϕ(X)∼Pϕ(Z^),Z∼N(0,I),gθ(Z)∼Pθ
In a Naive-GAN, Dw() classifies between X and g_θ(Z)
If we solely train the generator for the adversial objective, we may solve for the task of producing same representations for data points with same meaning well, but the produced representation may not be conducive for the classification task.
During inference, the same classifier can be used on both the source and target distributions, since the classifier is trained on domain-agnostic features.